 乐维官网
乐维官网
乐维监控 x Prometheus:解锁高效运维新技能
8191乐维监控对接Prometheus
View details热门搜索 企业动态 新闻中心 成功案例 社区 Prometheus交流区
这一期乐维君主要跟大家来探讨新一代的开源监控prometheus,我们知道 zabbix 在监控界占有不可撼动的地位,功能强大。但是对容器监控显得力不从心。为解决监控容器的问题,引入了 Prometheus 技术。接下来的文章打算围绕 Prometheus 做一个系列的介绍,顺便也帮自己理清一下知识点。
Prometheus官网上的自述是:“From metrics to insight.Power your metrics and alerting with a leading open-source monitoring solution.”翻译过来就是:从指标到洞察力,Prometheus通过领先的开源监控解决方案为用户的指标和告警提供强大的支持。通过PromQL实现多维度数据模型的灵活查询。 定义了开放指标数据的标准,自定义探针(如Exporter等),编写简单方便。 PushGateway组件让这款监控系统可以接收监控数据。 提供了VM和容器化的版本。 尤其是第一点,这是很多监控系统望尘莫及的。多维度的数据模型和灵活的查询方式,使监控指标可以关联到多个标签,并对时间序列进行切片和切块,以支持各种图形、表格和告警场景。
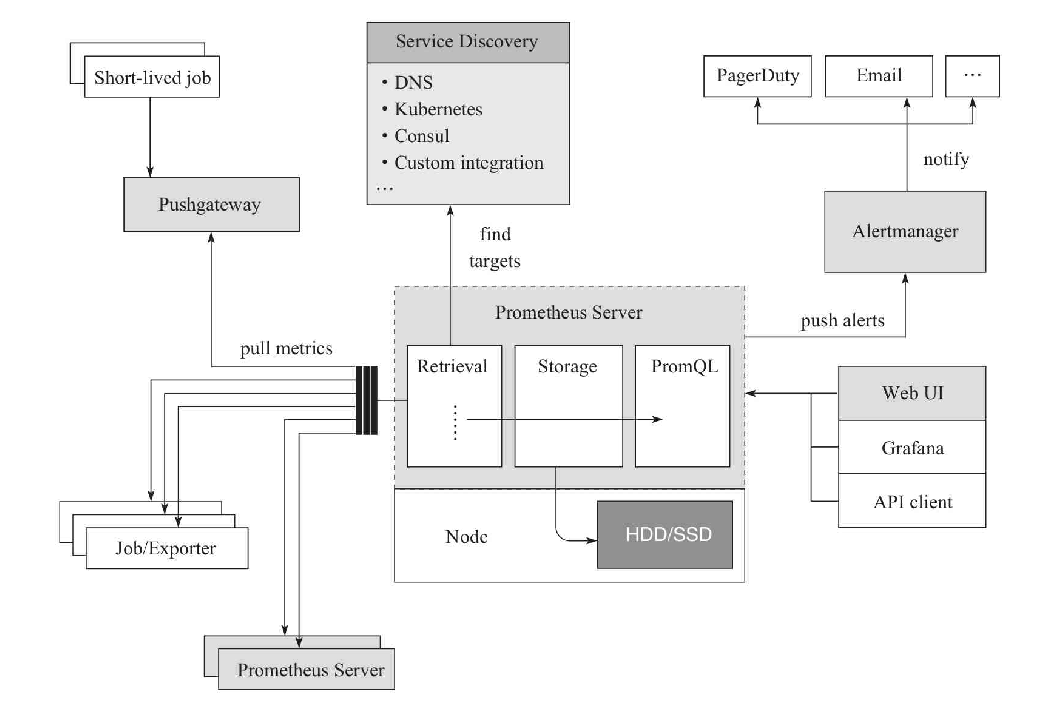
Prometheus主要由Prometheus Server、Pushgateway、Job/Exporter、Service Discovery、Alertmanager、Dashboard这6个核心模块构成。Prometheus通过服务发现机制发现target,这些目标可以是长时间执行的Job,也可以是短时间执行的Job,还可以是通过Exporter监控的第三方应用程序。被抓取的数据会存储起来,通过PromQL语句在仪表盘等可视化系统中供查询,或者向Alertmanager发送告警信息,告警会通过页面、电子邮件、钉钉信息或者其他形式呈现。
从上述架构图中可以看到,Prometheus不仅是一款时间序列数据库,在整个生态上还是一套完整的监控系统。对于时间序列数据库,在进行技术选型的时候,往往需要从宽列模型存储、类SQL查询支持、水平扩容、读写分离、高性能等角度进行分析。而监控系统的架构,往往还需要考虑通过减少组件、服务来降低成本和复杂性以及水平扩容等因素。
很多企业自己研发的监控系统中往往会使用消息队列Kafka和Metrics parser、Metrics process server等Metrics解析处理模块,再辅以Spark等流式处理方式。应用程序将Metric推到消息队列(如Kafaka),然后经过Exposer中转,再被Prometheus拉取。之所以会产生这种方案,是因为考虑到有历史包袱、复用现有组件、通过MQ(消息队列)来提高扩展性等因素。这个方案会有如下几个问题。
增加了查询组件,比如基础的sum、count、average函数都需要额外进行计算。这一方面多了一层依赖,在查询模块连接失败的情况下会多提供一层故障风险;另一方面,很多基本的查询功能的实现都需要消耗资源。而在Prometheus的架构里,上述这些功能都是得到支持的。 抓取时间可能会不同步,延迟的数据将会被标记为陈旧数据。如果通过添加时间戳来标识数据,就会失去对陈旧数据的处理逻辑。
Prometheus适用于监控大量小目标的场景,而不是监控一个大目标,如果将所有数据都放在Exposer中,那么Prometheus的单个Job拉取就会成为CPU的瓶颈。这个架构设计和Pushgateway类似,因此如果不是特别必要的场景,官方都不建议使用。 缺少服务发现和拉取控制机制,Prometheus只能识别Exposer模块,不知道具体是哪些target,也不知道每个target的UP时间,所以无法使用Scrape_*等指标做查询,也无法用scrape_limit做限制。
对于上述这些重度依赖,可以考虑将其优化掉,而Prometheus这种采用以拉模式为主的架构,在这方面的实现是一个很好的参考方向。同理,很多企业的监控系统对于cmdb具有强依赖,通过Prometheus这种架构也可以消除标签对cmdb的依赖。
Job/Exporter属于Prometheus target,是Prometheus监控的对象。
Job分为长时间执行和短时间执行两种。对于长时间执行的Job,可以使用Prometheus Client集成进行监控;对于短时间执行的Job,可以将监控数据推送到Pushgateway中缓存。
Prometheus收录的Exporter有上千种,它可以用于第三方系统的监控。Exporter的机制是将第三方系统的监控数据按照Prometheus的格式暴露出来,没有Exporter的第三方系统可以自己定制Exporter。
Exporter种类繁多,每个Exporter又都是独立的,每个组件各司其职。但是Exporter越多,维护压力越大,尤其是内部自行开发的Agent等工具需要大量的人力来完成资源控制、特性添加、版本升级等工作。
针对以上问题,可以考虑用Influx Data公司开源的Telegra统一进行管理。Telegraf是一个用Golang编写的用于数据收集的开源Agent,其基于插件驱动。Telegraf提供的输入和输出插件非常丰富,当用户有特殊需求时,也可以自行编写插件(需要重新编译)。
Telegraf就是Influx Data公司的时间序列平台TICK(一种高性能时序中台)技术栈中的“T”,主要用于收集时间序列型数据,比如服务器CPU指标、内存指标、各种IoT设备产生的数据等。Telegraf支持各种类型Exporter的集成,可以实现Exporter的多合一。还有一种思路就是通过主进程拉起多个Exporter进程,仍然可以跟着社区版本进行更新。
Telegraf的CPU和内存使用率极低,支持几乎所有的集成监控和丰富的社区集成可视化,如Linux、Redis、Apache、StatsD、Java/Jolokia、Cassandra、MySQL等。由于Prometheus和InfluxDB都是时间序列存储监控系统,可以变通地将Telegraf对接到Prometheus中。在实际POC环境验证中,使用Telegraf集成Prometheus比单独使用Prometheus会拥有更低的内存使用率和CPU使用率。
Prometheus是拉模式为主的监控系统,它的推模式就是通过Pushgateway组件实现的。Pushgateway是支持临时性Job主动推送指标的中间网关,它本质上是一种用于监控Prometheus服务器无法抓取的资源的解决方案。它也是用Go语言编写的,在Apache 2.0许可证下开源。

Pushgateway作为一个独立的服务,位于被采集监控指标的应用程序和Prometheus服务器之间。应用程序主动推送指标到Pushgateway,Pushgateway接收指标,然后Pushgateway也作为target被Prometheus服务器抓取。它的使用场景主要有如下几种: 临时/短作业。 批处理作业。 应用程序与Prometheus服务器之间有网络隔离,如安全性(防火墙)、连接性(不在一个网段,服务器或应用程序仅允许特定端口或路径访问)。 Pushgateway与网关类似,在Prometheus中被建议作为临时性解决方案,主要用于监控不太方便访问到的资源。它会丢失很多Prometheus服务器提供的功能,比如UP指标和指标过期时进行实例状态监控。
Prometheus通过服务发现机制对云以及容器环境下的监控场景提供了完善的支持。
Prometheus会周期性地从文件中读取最新的target信息。
对于支持文件的服务发现,实践场景下可以衍生为与自动化配置管理工具(Ansible、Cron Job、Puppet、SaltStack等)结合使用。
Prometheus还支持多种常见的服务发现组件,如Kubernetes、DNS、Zookeeper、Azure、EC2和GCE等。例如,Prometheus可以使用Kubernetes的API获取容器信息的变化(如容器的创建和删除)来动态更新监控对象。
通过服务发现的方式,管理员可以在不重启Prometheus服务的情况下动态发现需要监控的target实例信息。
服务发现中有一个高级操作,就是Relabeling机制。Relabeling机制会从Prometheus包含的target实例中获取默认的元标签信息,从而对不同开发环境(测试、预发布、线上)、不同业务团队、不同组织等按照某些规则(比如标签)从服务发现注册中心返回的target实例中有选择性地采集某些Exporter实例的监控数据。
这句话的意思就是Relabeling机制可以让prometheus按照动态的按照某些规则采集指定监控数据。
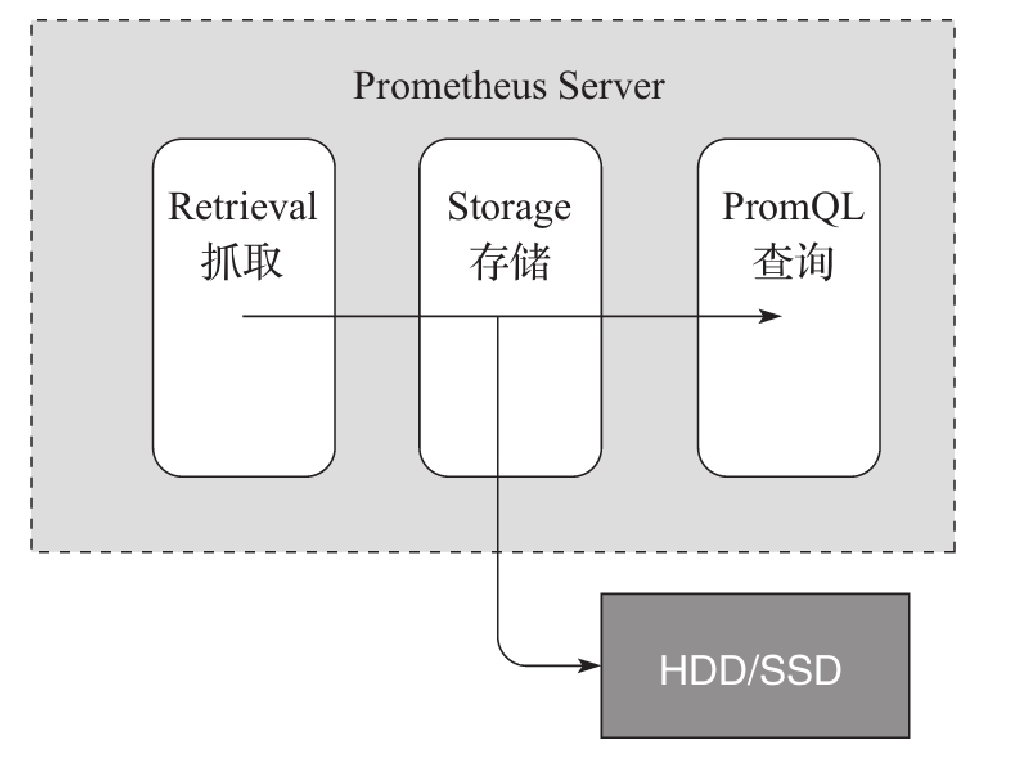
Prometheus服务器是Prometheus最核心的模块。它主要包含抓取、存储和查询这3个功能
Prometheus Server通过服务发现组件,周期性地从上面介绍的Job、Exporter、Pushgateway这3个组件中通过HTTP轮询的形式拉取监控指标数据。
抓取到的监控数据通过一定的规则清理和数据整理(抓取前使用服务发现提供的relabel_configs方法,抓取后使用作业内的metrics_relabel_configs方法),会把得到的结果存储到新的时间序列中进行持久化。多年来,存储模块经历了多次重新设计,Prometheus 2.0版的存储系统是第三次迭代。该存储系统每秒可以处理数百万个样品的摄入,使得使用一台Prometheus服务器监控数千台机器成为可能。使用的压缩算法可以在真实数据上实现每个样本1.3B。建议使用SSD,但不是严格要求。
本地存储:会直接保留到本地磁盘,性能上建议使用SSD且不要保存超过一个月的数据。记住,任何版本的Prometheus都不支持NFS。一些实际生产案例告诉我们,Prometheus存储文件如果使用NFS,则有损坏或丢失历史数据的可能。 远程存储:适用于存储大量的监控数据。Prometheus支持的远程存储包括OpenTSDB、InfluxDB、Elasticsearch、Graphite、CrateDB、Kakfa、PostgreSQL、TimescaleDB、TiKV等。远程存储需要配合中间层的适配器进行转换,主要涉及Prometheus中的remote_write和remote_read接口。在实际生产中,远程存储会出现各种各样的问题,需要不断地进行优化、压测、架构改造甚至重写上传数据逻辑的模块等工作。
Prometheus持久化数据以后,客户端就可以通过PromQL语句对数据进行查询了。
在Prometheus架构图中提到,Web UI、Grafana、API client可以统一理解为Prometheus的Dashboard。Prometheus服务器除了内置查询语言PromQL以外,还支持表达式浏览器及表达式浏览器上的数据图形界面。实际工作中使用Grafana等作为前端展示界面,用户也可以直接使用Client向Prometheus Server发送请求以获取数据。
Alertmanager是独立于Prometheus的一个告警组件,需要单独安装部署。Prometheus可以将多个Alertmanager配置为一个集群,通过服务发现动态发现告警集群中节点的上下线从而避免单点问题,Alertmanager也支持集群内多个实例之间的通信。

Alertmanager接收Prometheus推送过来的告警,用于管理、整合和分发告警到不同的目的地。Alertmanager提供了多种内置的第三方告警通知方式,同时还提供了对Webhook通知的支持,通过Webhook用户可以完成对告警的更多个性化的扩展。Alertmanager除了提供基本的告警通知能力以外,还提供了如分组、抑制以及静默等告警特性。
Prometheus固然强大,但它还是具有一定局限性的。
Prometheus作为一个基于度量的系统,不适合存储事件或者日志等,它更多地展示的是趋势性的监控。如果用户需要数据的精准性,可以考虑ELK或其他日志架构。另外,APM更适用于链路追踪的场景。
Prometheus认为只有最近的监控数据才有查询的需要,所有Prometheus本地存储的设计初衷只是保存短期(如一个月)的数据,不会针对大量的历史数据进行存储。如果需要历史数据,则建议使用Prometheus的远端存储,如OpenTSDB、M3DB等。
Prometheus在集群上不论是采用联邦集群还是采用Improbable开源的Thanos等方案,都没有InfluxDB成熟度高,需要解决很多细节上的技术问题(如耗尽CPU、消耗机器资源等问题),这也是本章开头提到的InfluxDB在时序数据库中排名第一的原因之一。部分互联网公司拥有海量业务,出于集群的原因会考虑对单机免费但是集群收费的InfluxDB进行自主研发。
总之,使用Prometheus一定要了解它的设计理念:它并不是为了解决大容量存储问题,TB级以上数据建议保存到远端TSDB中;它是为运行时正确的监控数据准备的,无法做到100%精准,存在由内核故障、刮擦故障等因素造成的微小误差
这一期的Prometheus技术分享到这就结束了,更多开源监控技术分享请持续关注乐维官网或乐维社区(https://forum.lwops.cn/)


通过Nginx反向代理是一个不错的选择。 本文乐维君将介绍通过Nginx反向代理增加401认证方式来实现加密登录。
View details
prometheus监控宿主机,使用node_exporter工具来暴露主机和因公程序上的指标; prometheus监控docker容器,通过Cadviso
View details
对于运维监控而言,除了监控展示以外,另一个重要的需求无疑就是告警了。良好的告警可以帮助运维人员及时的发现问题,处理问题并防范于未然,是运维工作中不...
View details
