 乐维官网
乐维官网
Prometheus技术分享——Prometheus通过Nginx加密登陆
11100通过Nginx反向代理是一个不错的选择。 本文乐维君将介绍通过Nginx反向代理增加401认证方式来实现加密登录。
View details热门搜索 企业动态 新闻中心 成功案例 社区 Prometheus交流区
Prometheus作为新生代的开源监控系统,慢慢成为了云原生体系的监控事实标准,也证明了其设计得到业界认可。但在多集群,大集群等场景下,Prometheus由于没有分片能力和多集群支持,还有Prometheus不支持长期存储、不能自动水平缩、大范围监控指标查询会导致Prometheus服务内存突增等。本文从Prometheus的单集群监控开始,介绍包括Prometheus的基本概念,基于联邦架构的多集群监控,基于Thanos的多集群监控等内容。
Prometheus的工作流程核心是,以主动拉取pull的方式搜集被监控对象的metrics数据(监控指标数据),并将这些metrics数据存储到一个内存TSDB(时间序列数据库)中,并定期将内存中的指标同步到本地硬盘。
基本架构如下图所示
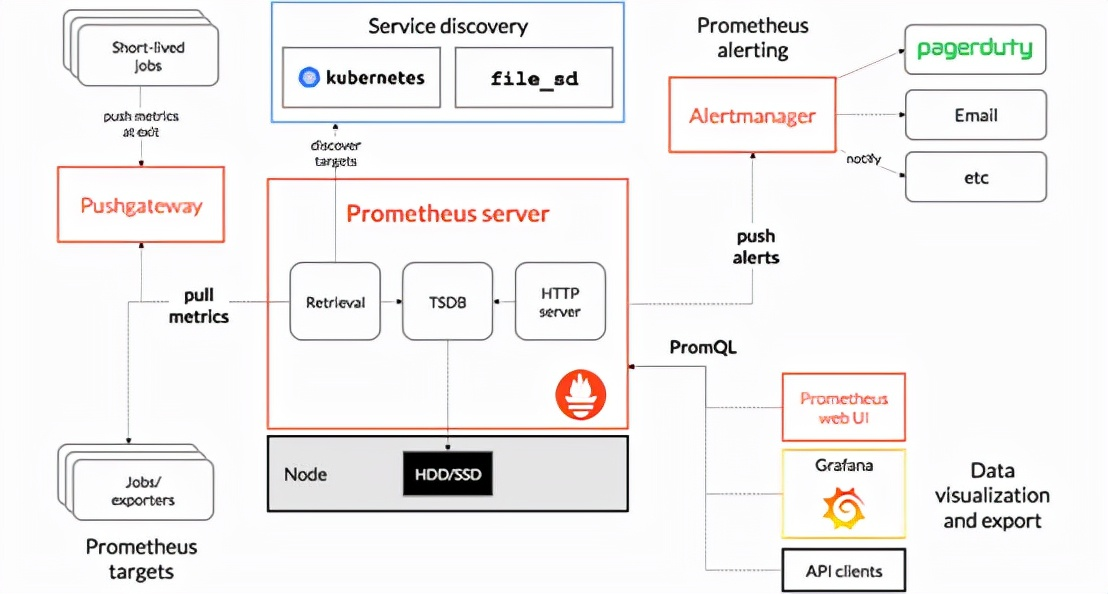
图可能有点复杂,简单总结如下:
从配置文件加载采集配置
周期性得往抓取对象发起抓取请求,得到数据
将数据写入本地盘或者写往远端存储
alertmanager从监控数据中发现异常数据做出报警
如果我们现在有多个集群,并希望他们的监控数据存储到一起,可以进行聚合查询,用上述部署方案显然是不够的,因为上述方案中的Prometheus只能识别出本集群内的被监控目标。另外就是网络限制,多个集群之间的网络有可能是不通的,这就使得即使在某个集群中知道另一个集群的地址,也没法去抓取数据,要解决这些问题那就得用高可用方案。
HA:即两套 Prometheus 采集完全一样的数据,外边挂负载均衡
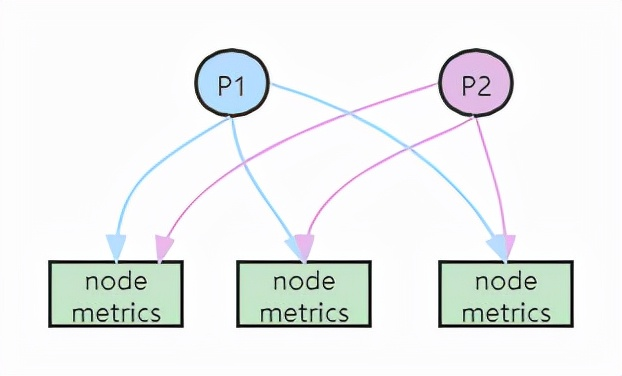
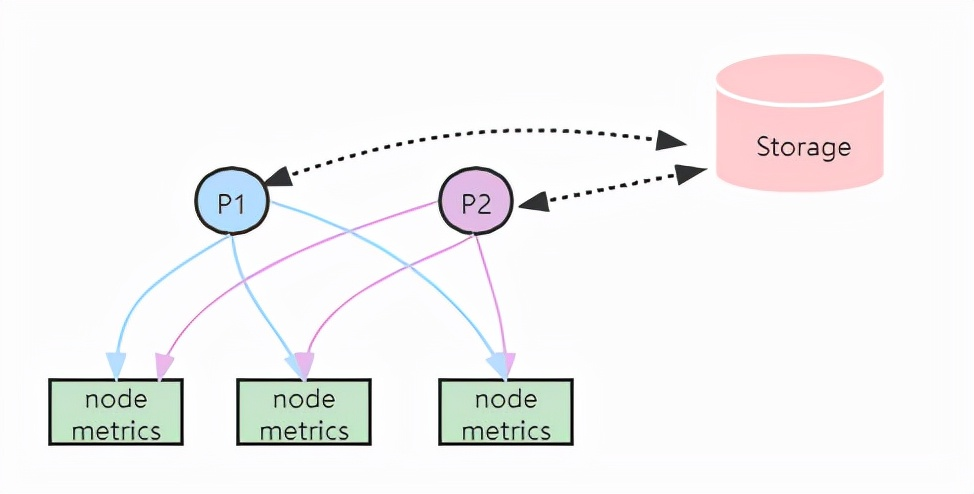
HA + 远程存储:Prometheus通过 Remote write 写入到远程存储
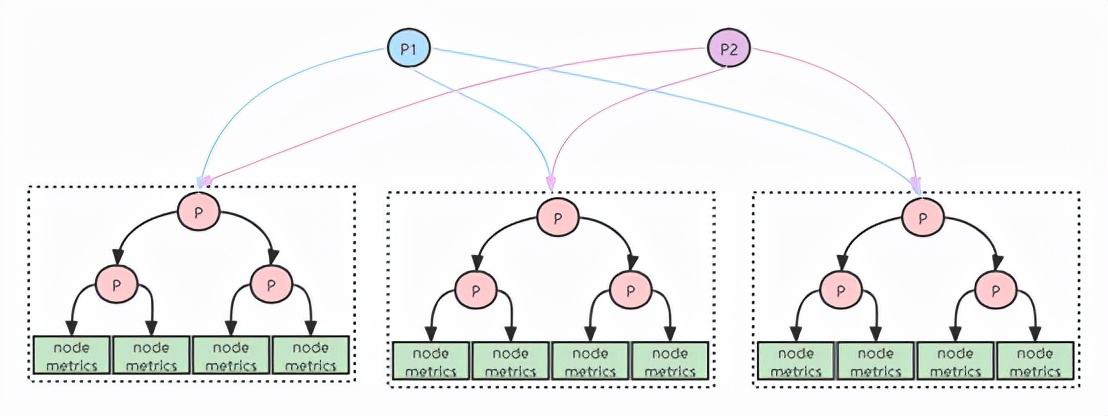
联邦集群:即 Federation,按照功能进行分区,不同的 Shard 采集不同的数据,由 Global 节点来统一存放,解决监控数据规模的问题。
使用官方建议的多副本 + 联邦仍然会遇到一些问题,本质原因是 Prometheus 的本地存储没有数据同步能力,要在保证可用性的前提下再保持数据一致性是比较困难的,基本的多副本 Proxy 满足不了要求,比如:
1.Prometheus 集群的后端有 A 和 B 两个实例,A 和 B 之间没有数据同步。A 宕机一段时间,丢失了一部分数据,如果负载均衡正常轮询,请求打到A 上时,数据就会异常。
2.如果A和B的启动时间不同,时钟不同,那么采集同样的数据时间戳也不同,就多副本的数据不相同
3.就算用了远程存储,A 和 B 不能推送到同一个 TSDB,如果每人推送自己的 TSDB,数据查询走哪边就是问题
4.官方建议数据做 Shard,然后通过 Federation 来实现高可用,但是边缘节点和 Global 节点依然是单点,需要自行决定是否每一层都要使用双节点重复采集进行保活。也就是仍然会有单机瓶颈。
1.长期存储:1 个月左右的数据存储,每天可能新增几十G,希望存储的维护成本足够小,有容灾和迁移。最好是存放在云上的 TSDB 或者对象存储、文件存储上。
2.无限拓展:我们有上百集群,几千节点,上万个服务,单机 Prometheus 无法满足,且为了隔离性,最好按功能做 Shard,如 Node机器监控与 K8S POD 资源等业务监控分开、主机监控与日志监控也分开,者按业务类型分开。
3.全局视图:按类型分开之后,虽然数据分散了,但监控视图需要整合在一起,一个Grafana 里n个面板就可以看到所有地域+集群的监控数据,操作更方便,不用多个Grafana的Dashboard 切来切去。
4.无侵入性:不会因为增加监控业务而重新加载Prometheus配置,因为重新加载Prometheus配置对Prometheus稳定是有风险的。
按照实例进行功能分区
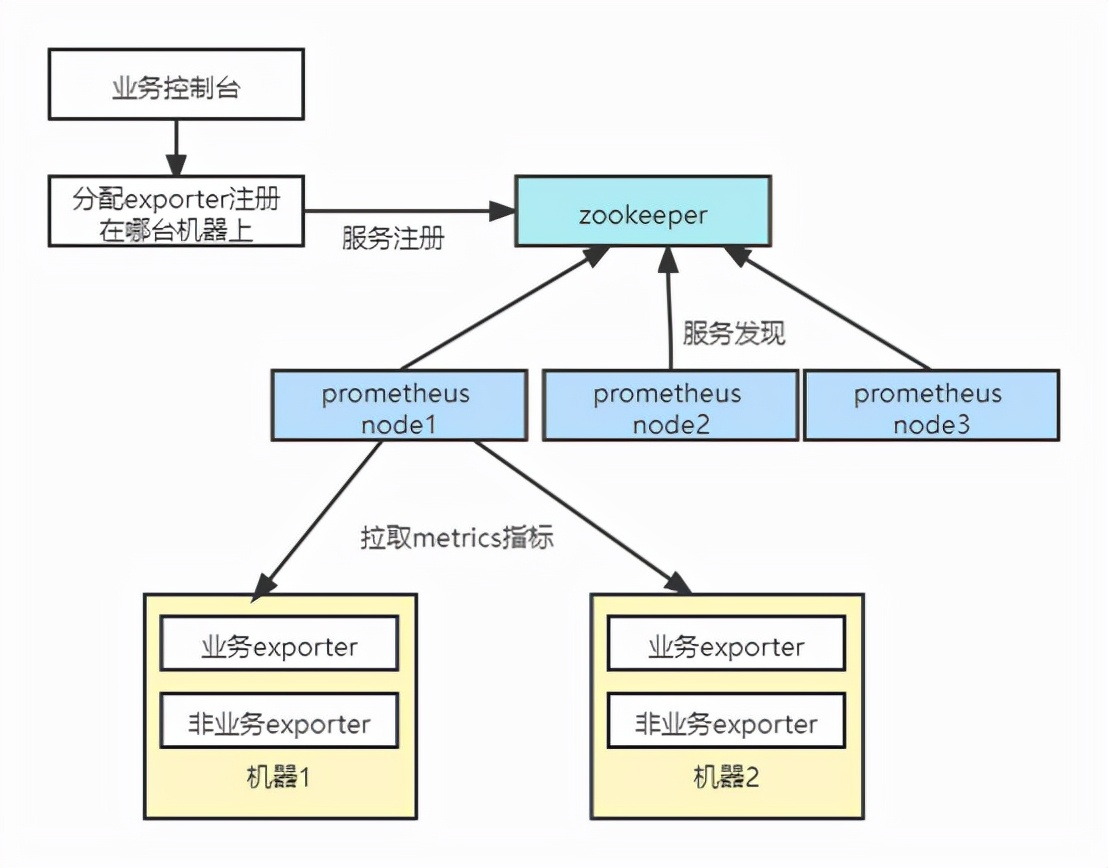
从图中看出,新增一台机器上报的metrics只需在zookeeper注册上报信息,prometheus自动发现新增的metrics,不需要重启prometheus或者重新加载prometheus配置。
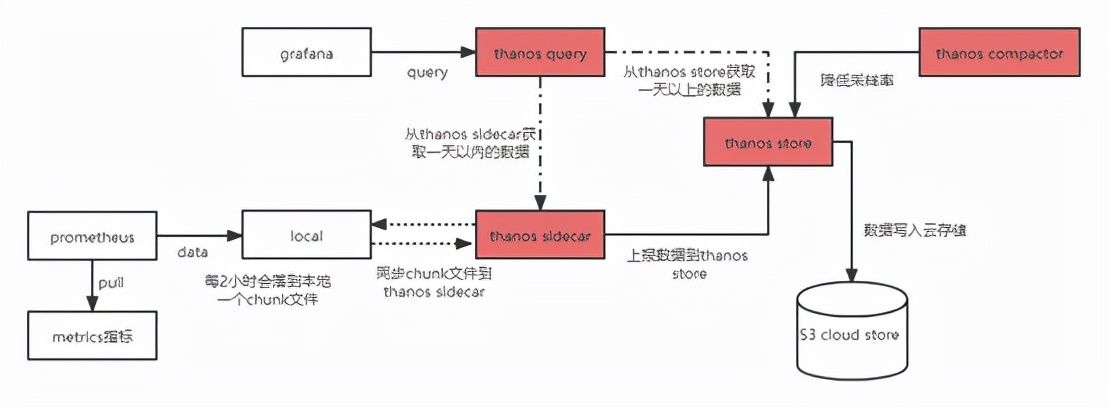
数据上报和查询
Prometheus会以固定频率去请求每个服务所提供的http url来获取数据,每2小时为一个时间单位,首先会存储到内存中,当到达2小时后,会自动写入磁盘中,prometheus采用的存储方式称为“时间分片”,每个block都是一个独立的数据库。
thanos sidecar监控prometheus本地block的chunks文件,当chunks文件有增加时thanos sidecar会将chunks数据通过grpc上传到thanos store,thanos store将接收到的数据落入S3云存储。
grafana向thanos query发起查询请求,thanos query从各个thanos sidecar拉取本地数据,并且通过thanos store从S3云存储上拉取历史数据,最后数据在thanos query进行汇总和去重返回给grafana。
如何保证架构稳定性
从数据上报和查询流程图中可以看到数据拉取和数据查询是分开的,prometheus只负责部分机器的数据拉取,当grafana有历史查询的需求的时候(比如查询三个月或者半年的数据),thanos query聚合后的数据存储在内存返回给grafana,当数据比较大时,thanos query服务器内存会写满导致服务不可用,但是prometheus还在以固定频率拉取metrics数据,这时候只需要重新恢复thanos query服务即可,不会对metrics数据连续性有任何影响。
Sidecar
Sidecar作为一个单独的进程和已有的Prometheus实例运行在一个server上,互不影响。Sidecar可以视为一个Proxy组件,所有对Prometheus的访问都通过Sidecar来代理进行。通过Sidecar还可以将采集到的数据直接备份到云端对象存储服务器。
Query
所有的Sidecar与Query直连,同时Query实现了一套Prometheus官方的HTTP API从而保证对外提供与Prometheus一致的数据源接口,Grafana可以通过同一个查询接口请求不同集群的数据,Query负责找到对应的集群并通过Sidecar获取数据。Query本身也是水平可扩展的,因而可以实现高可部署,而且Query可以实现对高可部署的Prometheus的数据进行合并从而保证多次查询结果的一致性,从而解决全局视图和高可用的问题。
Store
Store实现了一套和Sidecar完全一致的API提供给Query用于查询Sidecar备份到云端对象存储的数据。因为Sidecar在完成数据备份后,Prometheus会清理掉本地数据保证本地空间可用。所以当监控人员需要调取历史数据时只能去对象存储空间获取,而Store就提供了这样一个接口。
Comactor
由于我们有数据长期存储的能力,也就可以实现查询较大时间范围的监控数据,当时间范围很大时,查询的数据量也会很大,这会导致查询速度非常慢。通常在查看较大时间范围的监控数据时,我们并不需要那么详细的数据,只需要看到大致就行。Thanos Compact 这个组件应运而生,它读取对象存储的数据,对其进行压缩以及降采样再上传到对象存储,这样在查询大时间范围数据时就可以只读取压缩和降采样后的数据,极大地减少了查询的数据量,从而加速查询。
可靠性
thanos sidecar 会记录已经拉取过的prometheus chunk文件,在prometheus新生成chunk文件的时候thanos sidecar会通过thanos store同步chunk数据到S3云存储,实现了metrics数据无限期保留,保证了数据的可靠性。
稳定性
Prometheus数据拉取和数据查询拆分,不会因为大查询导致Prometheus内存暴增后服务挂掉,影响数据拉取,出现metrics数据断层。
可维护性
运维和开发人员不用修改prometheus配置,所有操作通过业务控制台维护zookeeper数据完成。
可伸缩性
一台Prometheus node节点只拉取几十台服务器的metrics数据,随着业务规模的变化灵活调整Prometheus node节点的数量。
目前开源社区和市面上有很多Prometheus高可用方案,但是都不能完全满足需求,随着我们的集群规模越来越大,监控数据的种类和数量也越来越多。更多prometheus相关技术资料,请持续关注乐维社区和prometheus技术分享。


通过Nginx反向代理是一个不错的选择。 本文乐维君将介绍通过Nginx反向代理增加401认证方式来实现加密登录。
View details
这一期乐维君主要跟大家来探讨新一代的开源监控prometheus,我们知道 zabbix 在监控界占有不可撼动的地位,功能强大。但是对容器监控显得力不从心。为解决监...
View details
对于运维监控而言,除了监控展示以外,另一个重要的需求无疑就是告警了。良好的告警可以帮助运维人员及时的发现问题,处理问题并防范于未然,是运维工作中不...
View details
